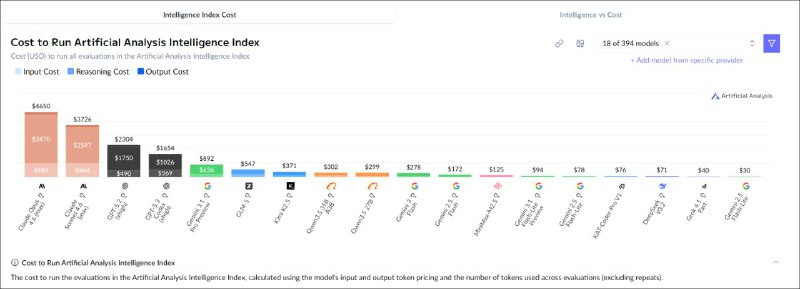
A new version of Gemini 3.1 Flash Lite has been released — and this is truly a notable event. This model confidently maintains its leadership in its segment both in benchmark results and in processing speed: it can generate approximately 400 tokens per second. It has a very long context window — a full one million tokens, and the model can also work with images and audio. Compared to the previous version, the token price has increased slightly, but the model itself has become significantly less chatty. As a result, the actual costs of usage remain roughly the same as before, unlike the larger Gemini 3 Flash, which is more expensive.
Created with n8n:
https://cutt.ly/n8n
Created with syllaby:
https://cutt.ly/syllaby