Google proposes a new way to make large language models smarter during dialogue
There is a well-known problem: modern LLMs struggle to update their beliefs as they receive new information. The model is expected to consider user preferences based on their responses and become more useful over time, but in practice, these models face significant difficulties with this.
Technically speaking, they lack a Bayesian approach to knowledge updating. That is, they are unable to revise their probability estimates of hypotheses when new data appears. Humans, on the other hand, are well-equipped for this — we can do exactly that, re-evaluating the likelihood of a hypothesis based on new facts.
The researchers proposed an interesting idea. Instead of training the model to update its knowledge through standard fine-tuning on dialogues, they decided to “embed” the functioning of a true Bayesian algorithm within it. What does this mean?
First, they create a classic Bayesian automaton — familiar to many who have studied traditional machine learning. It simply recalculates hypothesis probabilities using a specific formula when new data appears.
Then, they train the LLM on the responses of this algorithm — that is, it memorizes its logic and the principle of how it updates estimates, but without using the formula itself. As a result, the model learns an update strategy through training, rather than explicit programming.
Imagine a task: determining which movies a user likes — action, comedy, or drama. Initially, all probabilities are equal — 33%. The model presents three different movies from these genres, and the user chooses an action film. It is also known what the probability of choosing an action is given each genre preference: for example, 80%, 20%, and 30%. The Bayesian algorithm updates the probabilities using its formula, resulting in roughly 62%, 23%, and 15%. These new estimates inform the system — or the model — that the preference for that genre has increased. And so on.
Gradually, the model “learns” to behave like a Bayesian automaton — it internalizes the update logic and begins to apply it in other tasks without additional training.
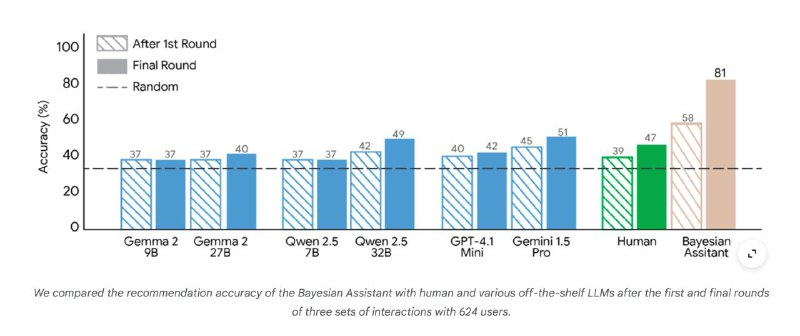
The results were quite impressive: the model indeed starts responding more accurately to new information, approaching the Bayesian ideal. This is especially noticeable in recommendation tasks: accuracy significantly improved. Interestingly, it also generalizes the acquired knowledge and applies it in other situations where it was not directly trained.
Overall, the research demonstrates that training models with demonstrations of algorithms is effective. Moreover, it confirms the idea that LLMs should be not only text generators but also universal imitators of reasoning and thought processes. This approach opens new horizons for AI development and makes systems more flexible in processing information.
Created with n8n:
https://cutt.ly/n8n
Created with syllaby:
https://cutt.ly/syllaby