MoonshotAI has devised a new approach to attention that could change the way transformers are understood.
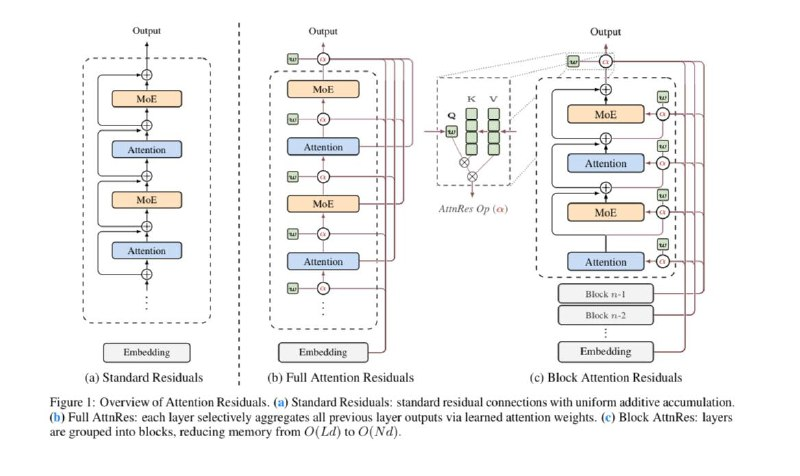
A key component of transformer architecture is the residual connection. Essentially, instead of each layer completely replacing the input signal with its output, the input is added to the layer’s output. This allows signals and gradients to flow easily through the entire depth of the model without distortion or vanishing. It is one of the fundamental ideas behind transformer architectures.
However, a research team from Moonshot (who, by the way, created Kimi K2) noticed that standard residual connections are too simple and somewhat “dumb.” They are indeed useful, but in practice, they simply accumulate all previous layer outputs without discrimination. As a result, with increasing depth, the contribution of each subsequent layer becomes diluted, and hidden states begin to grow uncontrollably.
To address this, they proposed the concept of Attention Residuals. The idea: let each layer decide which past outputs to attend to. It’s analogous to the familiar attention mechanism—only instead of focusing on tokens within a text, it focuses on the layers of the neural network.
Now, instead of receiving all information from previous layers at once, each layer selects a weighted sum of the relevant “hints”—the outputs that are most pertinent at that moment. Theoretically, this makes a lot of sense: if regular attention helps select relevant tokens within text, why not give the model the ability to choose the most important layers?
Of course, there is a caveat: this idea requires significant memory and computational resources. Therefore, engineers refined the concept slightly—retaining standard residual connections within blocks, while applying the attention mechanism only between these blocks.
In practice, this model has shown promising results—it converges faster and reaches a loss level comparable to that of a baseline model trained with approximately 25% more resources. In simple terms: Attention Residuals enable faster training without sacrificing quality. The authors also note that this idea makes the training process more stable and pleasant.
The work appears promising and potentially important for the future development of transformers. It will be interesting to observe how this idea is further applied.
Created with n8n:
https://cutt.ly/n8n
Created with syllaby:
https://cutt.ly/syllaby