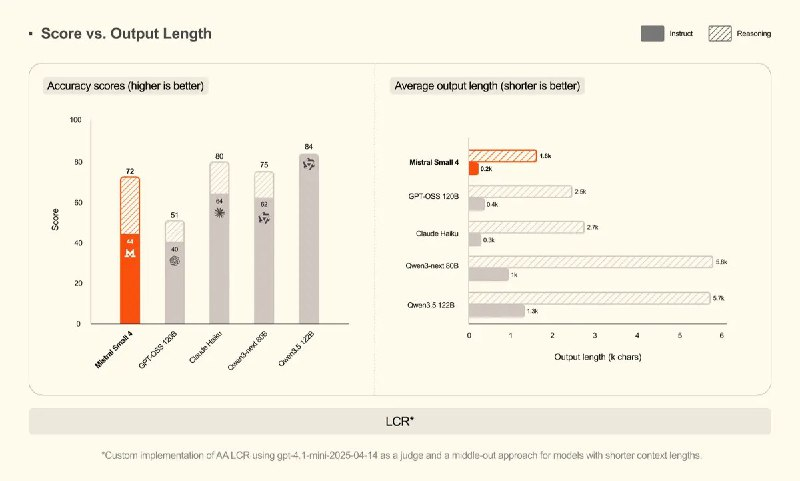
The Mistral Small 4 model has already been released, and frankly, the situation is somewhat disappointing. In published benchmarks, it performs worse than the September Qwen 3 Next — the latter has roughly one and a half times fewer parameters and even twice fewer active elements.
This multimodal model can process up to 256,000 tokens in context. Its architecture is the same as that of the DeepSeek V3 variant used in Large 3. For those interested in working with the code, the model is available under the Apache 2.0 license. However, the basic version was not fully released; instead, a special “head” for speculative decoding was prepared — an experimental tool for various scenarios.
Regarding technical details — the model weights are implemented in FP8 and NVFP4.
Created with n8n:
https://cutt.ly/n8n
Created with syllaby:
https://cutt.ly/syllaby