How to run a random model on your own computer independently?
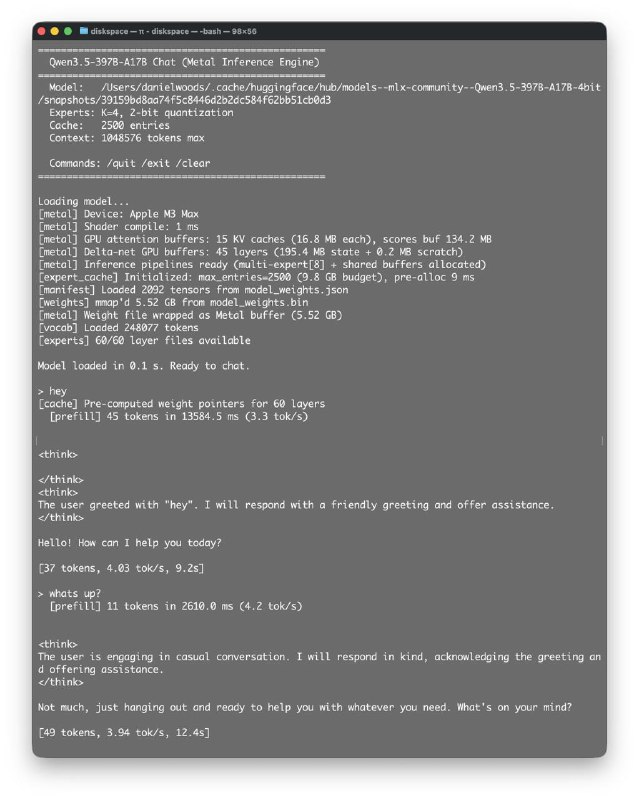
You can take an example from Dan Woods, who decided to run Qwen3.5-397B on his M3 Max with 48 GB of RAM (he mentioned this in a tweet).
He chose Claude Code, accessed the autoresearch repository by Andrej Karpathy, read Apple’s article “LLM in a Flash,” and thought: why not do the same?
After about five hours, the system was up and running, producing roughly one token per second. Another three hours of work and optimizations increased the speed almost fivefold — up to 4.74 tokens per second, while using around 6 GB of RAM. It’s worth noting that many improvements have not even been implemented yet.
Now, it can be said — a huge thanks to those who have manually created such optimizations in the past and made them accessible to all of us.
All of this is possible thanks to the efforts of those who have been working on it for a long time.
Created with n8n:
https://cutt.ly/n8n
Created with syllaby:
https://cutt.ly/syllaby