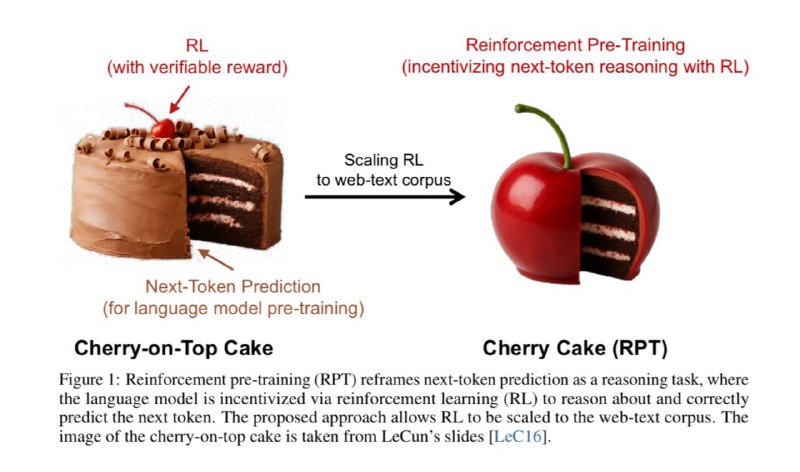
The new wave of approaches to pretraining large language models (LLMs) is attracting increasing attention, especially thanks to a recent paper by researchers from Microsoft and Beijing University. In the classical setting, pretraining involves the model learning to predict the next token as accurately as possible, based on the context — essentially, it’s just trying to guess what comes next and then comparing its predictions to real data.
However, in this work, the authors propose a fundamentally different perspective. They introduce the concept called “next-token reasoning” — almost adding reinforcement learning directly during the early stages of training. The idea is simple: from the very beginning, even before the model becomes the final version, it learns not only to predict tokens but to think step-by-step and reason.
Specifically, during training, the model first forms a chain of logical thoughts or reasoning (coT), and only afterward produces the next token. The model is rewarded for accurately matching the correct sequence — effectively, internal reinforcement learning that encourages more meaningful reasoning.
These approaches deliver comparable performance outcomes: a model with, say, 14 billion parameters, achieves results close to what a twice as large model could produce. In terms of next-token prediction accuracy, such models outperform standard variants like R1-Distill-Qwen-14B and approach the results of more substantial counterparts such as R1-Distill-Qwen-32B.
Of course, training with this method requires significantly more computational resources and time. But an additional advantage is that, since the model has been trained to reason from early on, it is much better prepared for further reinforcement learning (RL) fine-tuning. As a result, models trained with reinforcement learning post-supervised training are many times more efficient compared to traditional models lacking this “reasoning” experience.
Overall, there is much to ponder, especially for those interested in the latest breakthroughs in neural network training. More details can be found on the arXiv link.