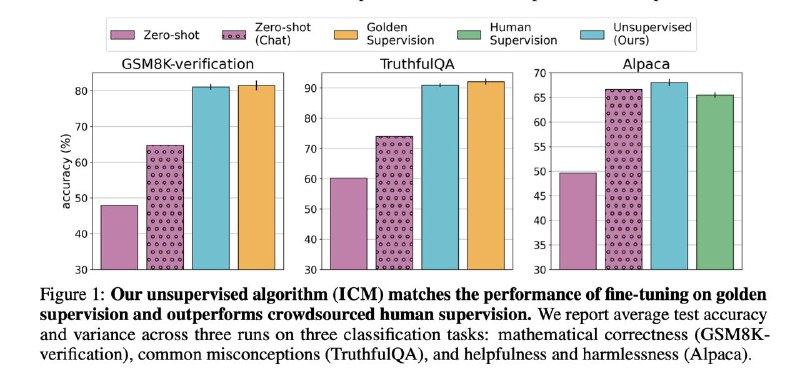
Anthropic and their partners from universities proposed a new approach to how models can learn independently without the constant need for manual data annotation. Typically, improving models requires large volumes of data annotated by humans, where specialists specify correct answers. However, as the flow of information increases and AI tasks become more complex, finding professional annotators becomes more challenging and costly. Moreover, data annotation itself increasingly raises concerns due to errors and subjectivity.
This is where Anthropic introduced the idea of the «Internal Coherence Maximization» algorithm, or ICM for short. Its key feature is that it allows models to “learn” and improve without human involvement in the annotation process. The term «coherence» from philosophy implies that everything in the world is interconnected and interdependent, and this concept underpins the new method. The model itself should choose the correct answer based on two main principles:
The first is mutual predictability. This means that each subsequent response should logically follow from the previous ones, and the model should be able to identify patterns and compare its answers with similar situations.
The second is logical consistency. The model checks its answers for contradictions to prevent logical discrepancies. For example, if it states that 2+3 equals 5, then claiming that 3+3 equals 5 would be incorrect.
And that’s all—nothing more, nothing less. During training, we show the model a small set of annotated data, and then it “learns” independently based on these two rules, producing results with minimal human involvement. As a result, such models sometimes outperform traditional fine-tuning with human-annotated data. For example, in a gender prediction test of text authors, where human accuracy usually does not exceed 60%, the model using this approach achieved about 80%.
Of course, this method works well with concepts familiar to the models and currently faces challenges when processing long context chains. Nevertheless, the prospects of its application are promising and demonstrate that the path toward more autonomous model training is becoming increasingly feasible.