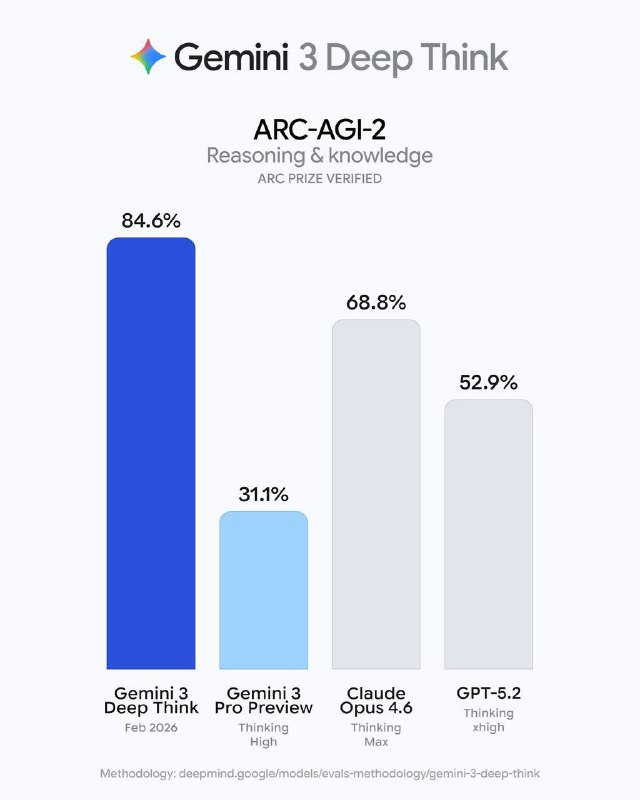
It’s been just about a year since the emergence of ARC-AGI-2, and significant changes have already taken place. Google released an updated version of their reasoning model Gemini 3 Deep Think, which immediately reached a high level and broke records on several test cases, including ARC-AGI-2 and HLE.
Let me remind you that roughly a year ago, the best models achieved only 1-2% of the maximum result on this benchmark. Now, Gemini 3 Deep Think’s score on ARC-AGI-2 has soared to 84.6%. It is generally considered that a benchmark is “saturated” or “solved” if a model scores over 80%, so it can be confidently said that ARC-AGI-2 is now a thing of the past. We are awaiting the release of the third version.
Of course, Google has once again delivered. Besides winning on ARC-AGI-2 and HLE, their model received a gold medal for written tasks at international physics and chemistry Olympiads. It also demonstrated a fantastic result—a rating of 3455 on Codeforces, significantly surpassing Claude Opus 4.6’s rating of around 2352—there’s plenty to compare.
Additionally, the new model has already been launched for subscribers of Google AI Ultra, so those in the know can try it personally and witness the power of the technology.
Created with n8n:
https://cutt.ly/n8n
Created with syllaby:
https://cutt.ly/syllaby