Microsoft is actively working on developing logical reasoning in artificial intelligence, and new methods enable models to learn to reason more effectively — from small to very large. The focus is on three key areas: creating compact architectures, improving mathematical accuracy, and expanding cross-domain generalization capabilities.
Special attention is given to small models (from 1.5 to 7 billion parameters), which need to learn to imitate the human step-by-step approach to problem-solving.
For example, within the rStar-Math project, the MCTS search algorithm is used during self-training. It involves breaking down complex tasks into individual steps, after which the model learns to evaluate their quality using a special labeling system — the Process Preference Model (PPM). Then, the strategy is iteratively improved through several cycles, allowing significant enhancement of solution quality in just four iterations.
Another tool is Logic-RL — a reinforcement learning framework that rewards the model only when it makes a fully correct and logical conclusion. This approach eliminates shortcuts and encourages strict adherence to correct logic.
To improve mathematical reliability, a hybrid mechanism called LIPS was developed, combining artificial intelligence and symbolic engines. In this framework, the language model handles pattern recognition and transforms conditions (such as inequalities), while the symbolic solver performs precise calculations — scaling or simplifying formulas.
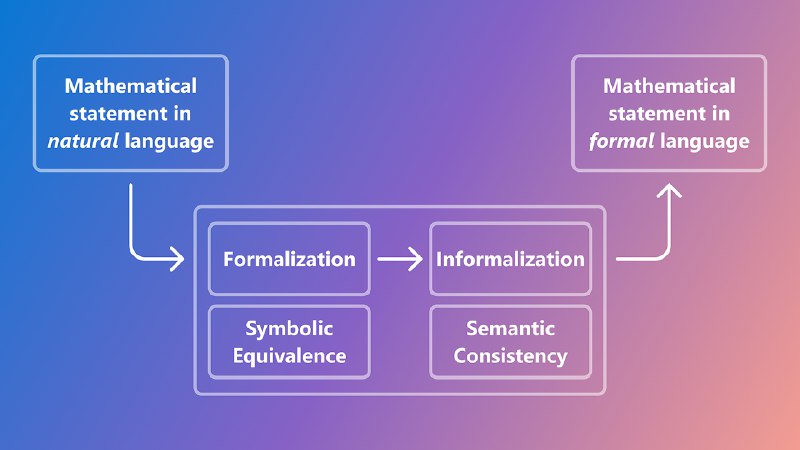
To ensure error-free understanding of conditions, a neuro-symbolic framework was created that generates training data: symbolic systems generate problems, and language models translate them into human-understandable text. Two methods are used to verify conclusions: comparing formulas for equivalence and analyzing their meaning through embeddings. This significantly increases system accuracy — by 35%.
An interesting effect is observed in another area: training on mathematics has greatly improved models’ abilities in programming and natural sciences.
To unify different approaches, a universal mechanism called Chain-of-Reasoning (CoR) was developed, which easily combines textual explanations, programmatic solutions, and symbolic reasoning within a single solution. Additionally, the Critical Plan Step Learning (CPL) technology was introduced to teach AI strategic thinking: breaking down complex tasks into key steps, highlighting important points, and discarding less promising options using planned search methods like MCTS and Step-APO.
Another article about these innovations is available in the Microsoft Research blog.