AMD Overview: The Future of Artificial Intelligence by 2025
Although Nvidia dominates the graphics processing market, competition still exists in this field. The most interesting developments currently on the horizon are:
➖ In Q3, new models MI350x and MI355x will debut — the same chips but with increased TDP. These cards will feature 288 GB of high-speed HBM3e memory, support for FP4 and FP6 formats, bandwidth of about 8 TB/s, and FP4 performance reaching 20 petaflops. Such cards will be able to hold over half a trillion parameters on board, which is impressive for a single configuration.
➖ These technical capabilities are bound to impact economics — AMD promises up to 40% increase in token processing per second at the same costs when compared to Nvidia Blackwell flagship models.
➖ In 2026, the release of MI400x is planned, boasting industry-record 40 petaflops in FP4 and 432 GB of HBM4 memory running at nearly 20 TB/s. The MI450 project is already under development in collaboration with OpenAI — a fact confirmed personally by Sam Altman during a presentation.
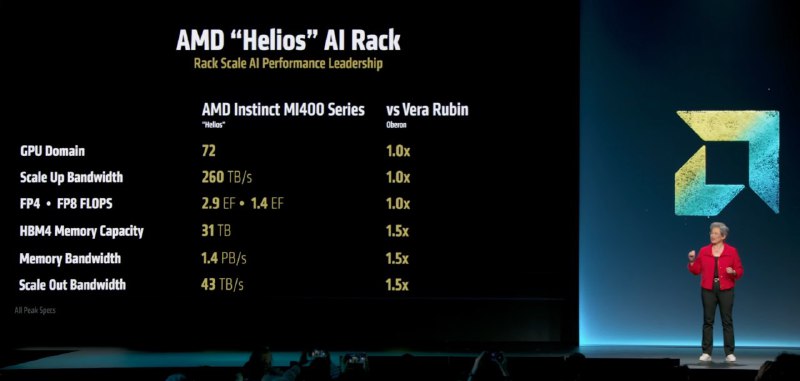
➖ Another ambitious project is Helios AI-Rack, which directly competes with Nvidia NVL144 Vera Rubin. It comprises 72 MI400x cards, collectively delivering approximately 2.9 exaflops in FP4. The system features a bandwidth of 1.4 petabytes per second and 31 TB of video memory, with an interconnect level comparable to NVLink. Its release is scheduled for 2026.
➖ The key point is that the entire Helios solution lineup is based on open interconnect standards, making it much more flexible and transparent than Nvidia’s proprietary solutions.
➖ AMD also offers its official cloud service, AMD Developer Cloud — a nearly complete hub for developers where registration can be simply done via GitHub. There, users can access the MI300x for just $2 per hour, which is significantly cheaper than competing offers.
Regarding AMD graphics cards — they look very promising for inference tasks: with comparable power to traditional GPUs, they offer larger VRAM capacity and higher bandwidth. This directly leads to larger batch sizes and reduced token processing costs. Over the past year, support for inference software solutions such as SGLang has grown notably, and systems based on AMD have demonstrated good stability. While training models on these systems is still early — instability persists — the progress is impressive.
The full presentation can be accessed there.